- Published on
👩💻 | 바닥부터 도전하는 모션 생성: VAE편
Variational Autoencoder
인코딩 된 부분들이 공백이 있는데, 이는 제대로 된 형태의 이미지로 디코딩으로 이어지지 않는다. VAE는 잠재공간의 한 공간으로 직접 매핑되는 AE와 달리 포인트 주변 multivariate nomral distribution에 맵핑된다.
아래에서 확인할 수 있듯 잠재 변수 전에 정규화 과정을 거친다.
| Autoencoder | Variational Autoencoder |
|---|---|
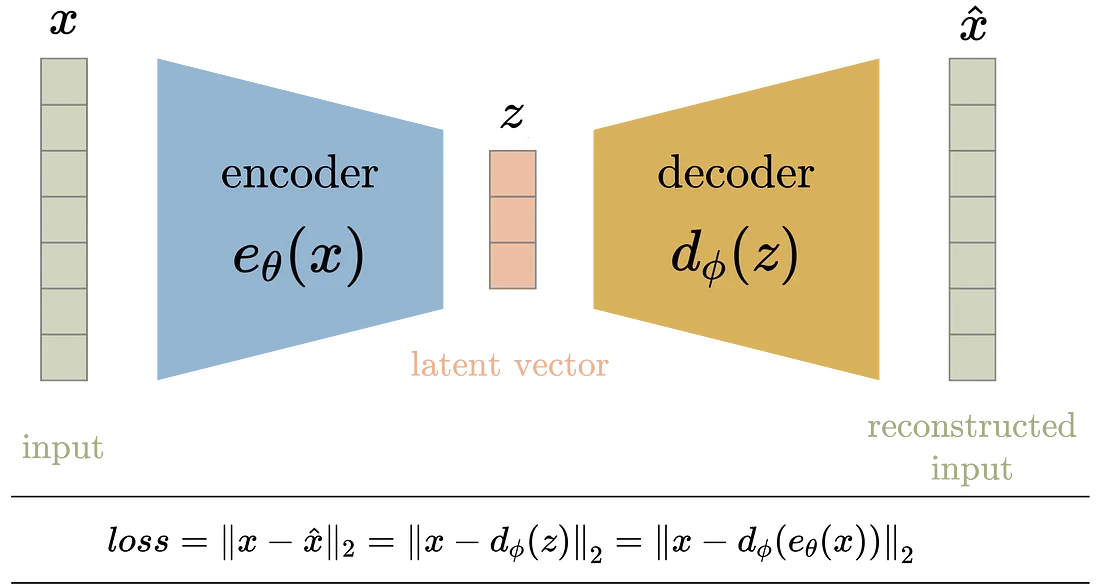 | 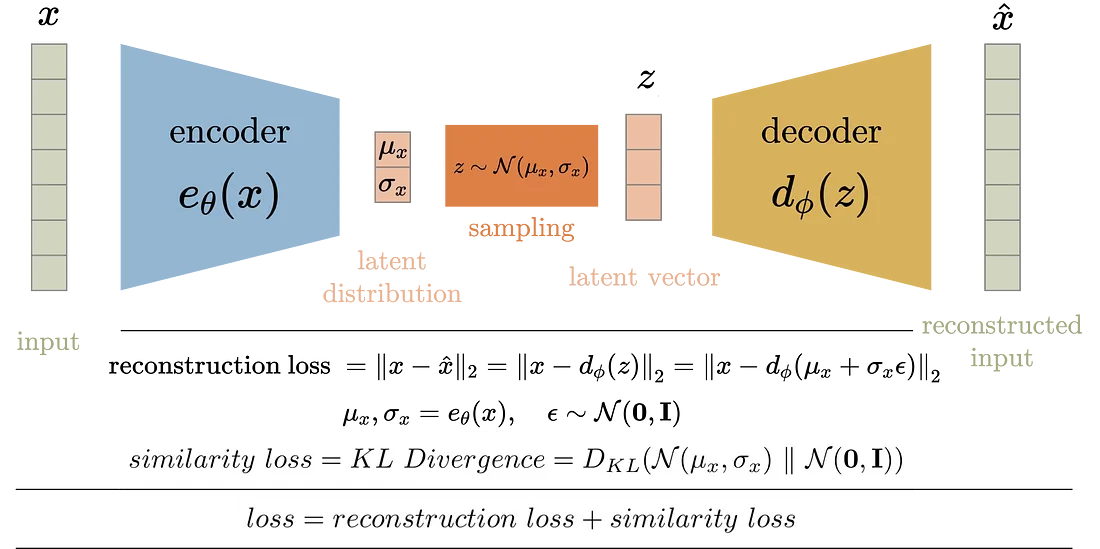 |
이는 Autoencoder에서 표현되는 latent space가 보다 고르게 분포할 수 있게 한다.
Data Acquisition & Preprocessing
본 논문에서 데이터는 명시하지 않았으나 일부 locomotion과 관련된 CMU mocap data를 사용하였다. 전반적인 전처리 과정은
- 120(cmu 기본 fps) -> 30fps로 sub-sample
- global에서 local position으로 transform 해서 사용
- local position = Global position - Root XZ position
- local position frame간 차이를 local velocity로 정의해서 사용
- 어깨와 힙의 방향 벡터를 더한 벡터값과 up vector의 외적 = forward 벡터로 정의
- 해당 forward vec과 z axis(forward) 기준으로 rotation 정의
- 각 local 정보에 rotation 적용(pose alignment)
- 데이터는 따라서 순서대로 root xz pos, root an
n이 데이터의 총 frames라고 했을 때, 데이터는 와 같다.
Motion Variational Autoencoder

모델은 Autoregressive Conditional Variational Autoencoder을 기반으로 하고 있다.
- Autoregressive: reconstructed된 포즈 정보를
- Condition: 이전 프레임 정보로 조건을 주는
구조로 크게 이루어져 있다.
Encoder
Encoder 구조는 VAE에서의 일반적인 autoencoder를 가진다. 아래는 직접 구현한 모델 summary이다.
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ previous_pose (InputLayer) │ (None, 375) │ 0 │ - │
├───────────────────────────────┼───────────────────────────┼─────────────────┼────────────────────────────┤
│ current_pose (InputLayer) │ (None, 375) │ 0 │ - │
├───────────────────────────────┼───────────────────────────┼─────────────────┼────────────────────────────┤
│ concat_poses (Concatenate) │ (None, 750) │ 0 │ previous_pose[0][0], │
│ │ │ │ current_pose[0][0] │
├───────────────────────────────┼───────────────────────────┼─────────────────┼────────────────────────────┤
│ encoder_layer1 (Dense) │ (None, 256) │ 192,256 │ concat_poses[0][0] │
├───────────────────────────────┼───────────────────────────┼─────────────────┼────────────────────────────┤
│ encoder_layer2 (Dense) │ (None, 256) │ 65,792 │ encoder_layer1[0][0] │
├───────────────────────────────┼───────────────────────────┼─────────────────┼────────────────────────────┤
│ encoder_layer3 (Dense) │ (None, 256) │ 65,792 │ encoder_layer2[0][0] │
├───────────────────────────────┼───────────────────────────┼─────────────────┼────────────────────────────┤
│ z_mean (Dense) │ (None, 32) │ 8,224 │ encoder_layer3[0][0] │
├───────────────────────────────┼───────────────────────────┼─────────────────┼────────────────────────────┤
│ z_log_var (Dense) │ (None, 32) │ 8,224 │ encoder_layer3[0][0] │
├───────────────────────────────┼───────────────────────────┼─────────────────┼────────────────────────────┤
│ sampling (Sampling) │ (None, 32) │ 0 │ z_mean[0][0], │
│ │ │ │ z_log_var[0][0] │
└───────────────────────────────┴───────────────────────────┴─────────────────┴────────────────────────────┘
Decoder
Decoder는 Mixture of Expert decoder 구조를 가지고 있다. 연구에서 참고된 이전 연구에서 [Zhang et al. 2018] 더 좋은 reconstructed된 결과를 보였다고 한다.
Consideration
Posterior collapse
본 논문에서는 previous pose 한 개를 토대로 조건을 주었지만, 여러 개의 조건을 줄 시, reconstruction 품질은 올라갈 수 있다고 한다. 하지만, 다양성을 줄일 수 있으며, encoder의 결과를 무시하게 되는 posterior collapse로 이어질 수 있다. 또한 latent variable을 모든 expert 네트워크에 latent 변수를 지나가게 설계하였다.
def forward(self, z, c):
coefficients = F.softmax(self.gate(torch.cat((z, c), dim=1)), dim=1)
layer_out = c.
for (weight, bias, activation) in self.decoder_layers:
...
input = torch.cat((z, layer_out), dim=1).unsqueeze(1)
. ...
return layer_out
Motion quality and generalization
결과물 품질은 reconstruction과 kl loss trade off로 이루어지는데, 품질이 더 높을 수록 synthesis가 이루어지지 않을 수 있다.
- Reconstruction loss: 원본 데이터로부터 얼마나 잘 reconstruct되는지 error
- KL divergence loss: 이전 distribution에 얼마나 현재 latent space와 얼마나 다른지에 대한 error
이 둘의 loss 기준으로 latent space가 잘 만들어졌는지에 대한 기준은 one order of magnitude 즉, 두 loss가 10배 이내 차이를 보이면 heuristic하게 훈련 결과 유추가 가능하다.
Training stability
훈련의 안정성을 위해 3단계로 나뉘어 훈련한다. autoregression이 들어가는 과정에서 시간이 지날 수록 예측이 점점 불안정한 문제를 지니고 있다. 이는 loss가 누적이 되어서 조건이 들어가게 되므로, 결과 데이터가 점점 이상해지게 된다.
그래서 단계 별로 예측 결과를 입력으로 사용하는 비율을 점차 늘리는 방향으로 훈련 방향을 제시하고 있다.
sample_schedule = torch.cat(
(
# First part is pure teacher forcing
torch.zeros(teacher_epochs),
# Second part with schedule sampling
torch.linspace(0.0, 1.0, ramping_epochs),
# last part is pure student
torch.ones(student_epochs),
)
)
Synthesis: Reinforcement learning
본 연구에서 재구성된 잠재변수를 통해 원하는 행동으로 제어를 강화학습을 통해 가능함을 보여준다. 보상함수에서는 보통 exp함수를 쓰게 되는데, 이는 자연스러운 보상과 지수에 들어가는 1에 근접할 수록 기하급수적으로 보상을 많이 줌으로써, 그에 맞게 행동이 제어되고 학습을 한다.
자체 실험에서는 제공된 두 가지 환경, Target Environment과 Joystick Environment 두 개만 실험을 진행하였다.
Train
논문과 다르게 설정한 hyperparameter는 아래와 같다.
LOCOMOTION_SUBJECTS = [2, 9, 16, 35, 38]
HIDDEN_UNITS = 256
LATENT_DIM = 32 # can impact likelihood of posterior collapse
NUM_EXPERTS = 6
BATCH_SIZE = 64
EPOCHS = 140
BETA = 0.2
FRAME_SIZE = 375
NUM_CONDITION_FRAMES = 1
NUM_FUTURE_PREDICTIONS = 1
locomotion 데이터는 running category만 데이터를 넣었다. 이전 대학원에서 실험한 결과, VAE 다른 category로 쉽게 transition을 하지 못하는 모습을 봤었는데, 이는, 다양하고 복잡한 데이터를 하나의 정규분포로 압축하려 하기 때문이다. 그 결과, 동작 사이를 부드럽게 이어주기보다 흐릿하거나 어색한 결과가 나오는 것을 확인했다. 논문 limitation에서 적혀있듯, 만약 해당 카테고리의 데이터가 현저히 적으면, 이러한 동작을 잘 찾지 못하여 one-hot encoding과 같이 별도의 condition을 주는 방법으로 학습하였다고 한다.
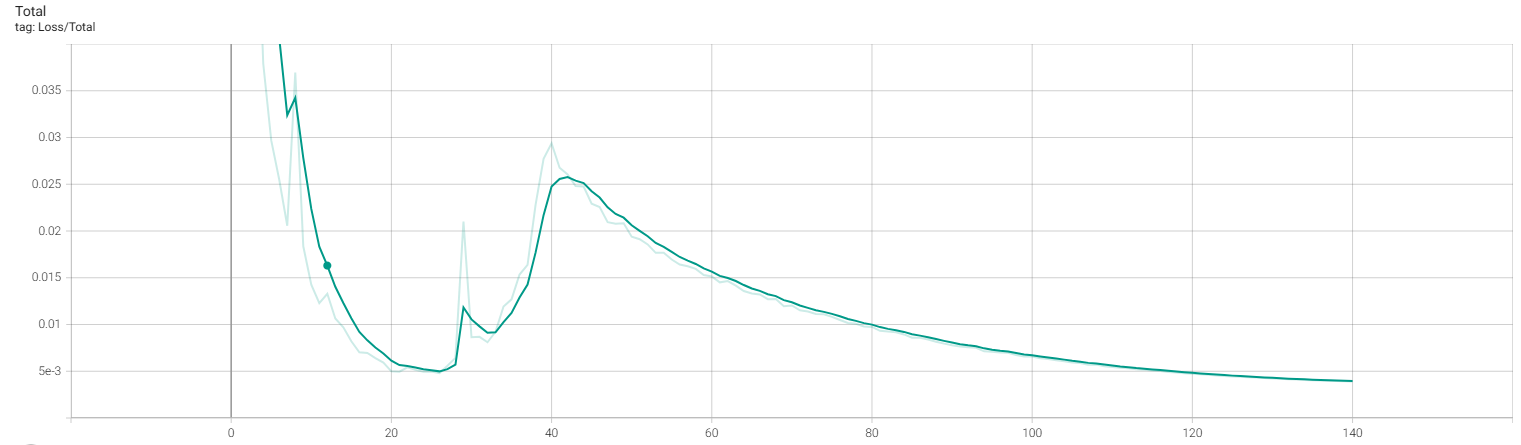
RTX 5060 환경에서 학습하였으며 CVAE는 약 50분이 소요되었고, controller는 약 4시간 30분 가량 소요가 되었다.
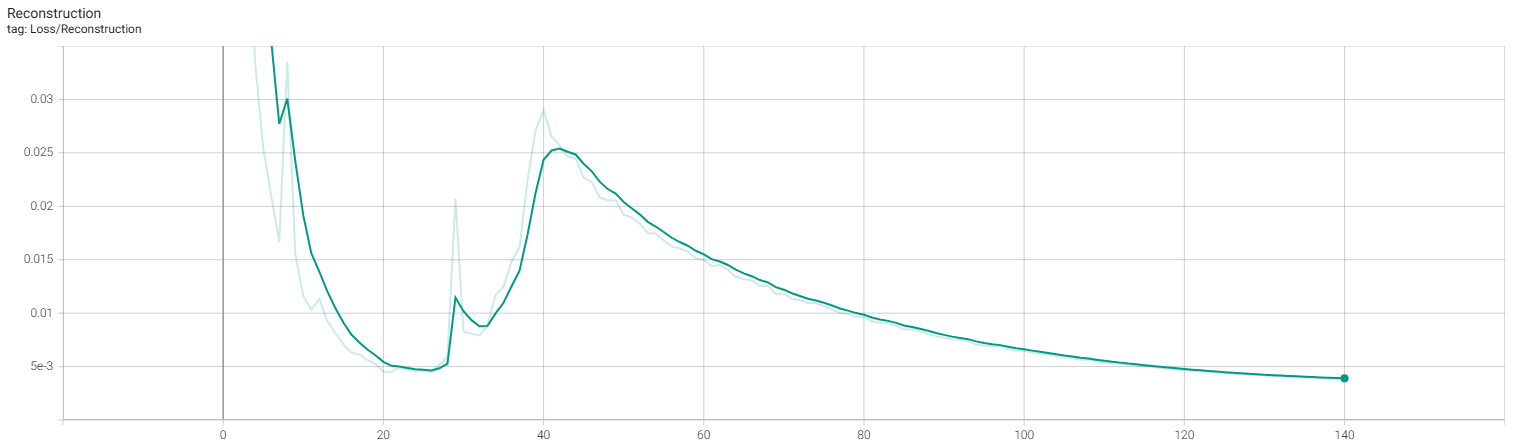
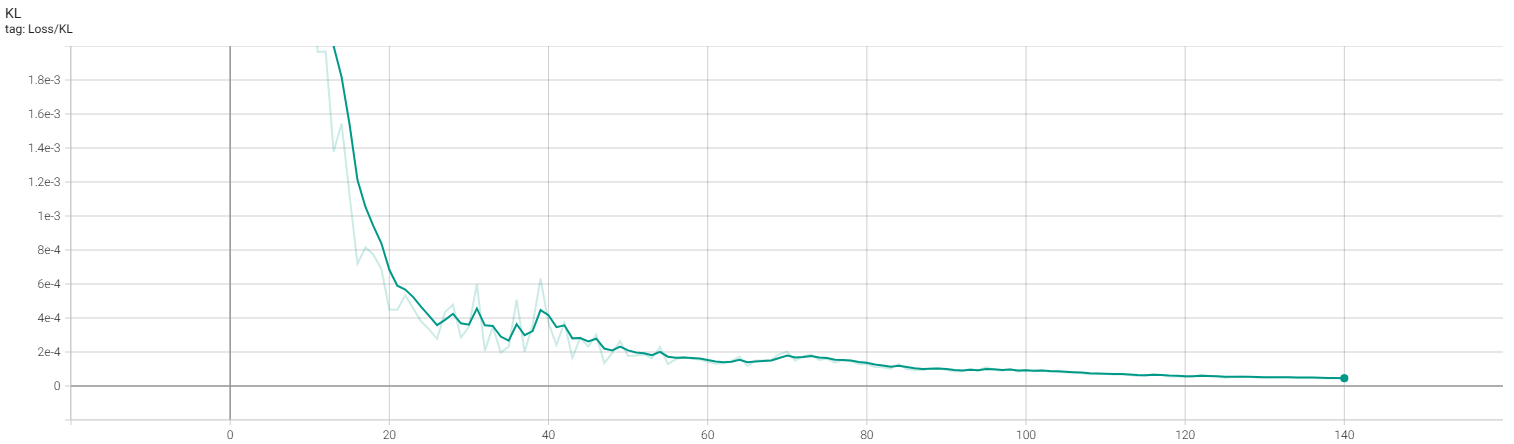
CVAE training
| Reconstruction Loss | KL-divergence Loss | Total Loss |
|---|---|---|
 |  |  |
Result

확실히 window 사이즈로 들어가던 이전 autoencoder에서 훈련한 결과와 달리, 하나의 frame 조건으로 reconstuction이 잘된 모습이다.
| Target Environment | Joystick Environment |
|---|---|
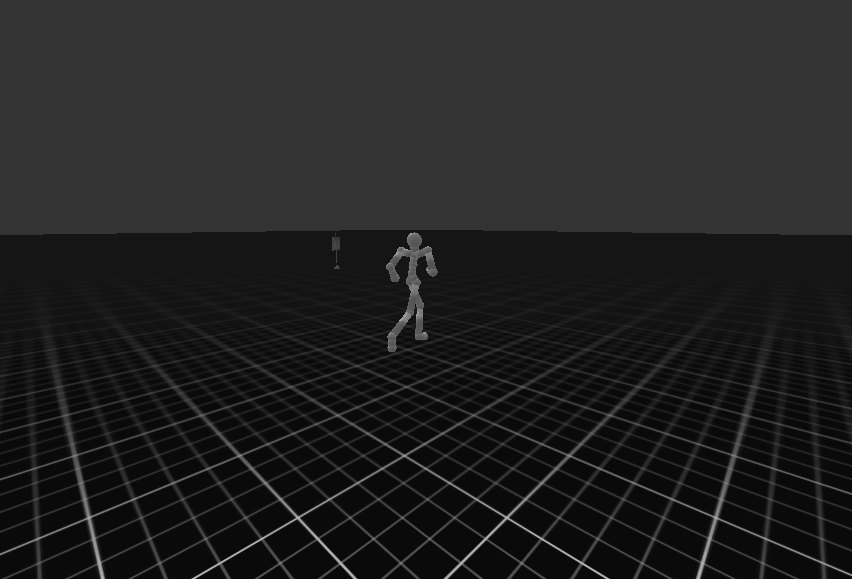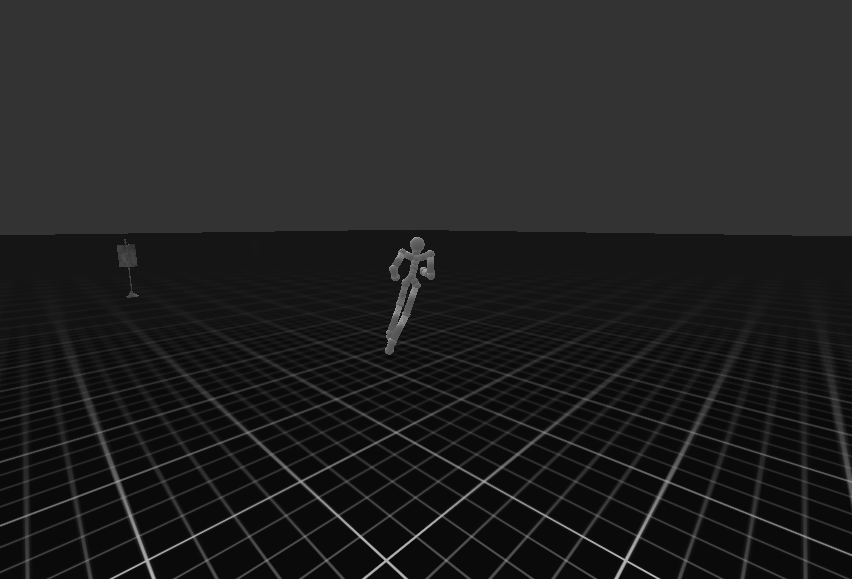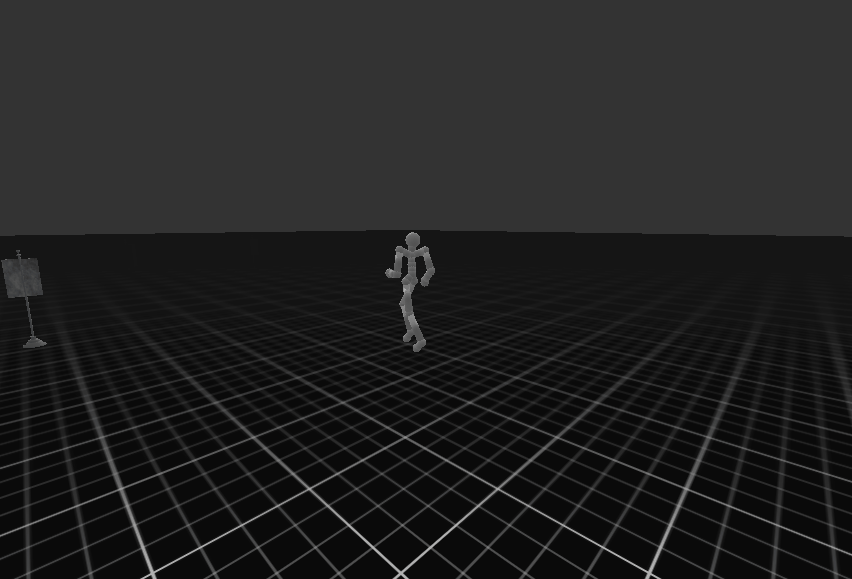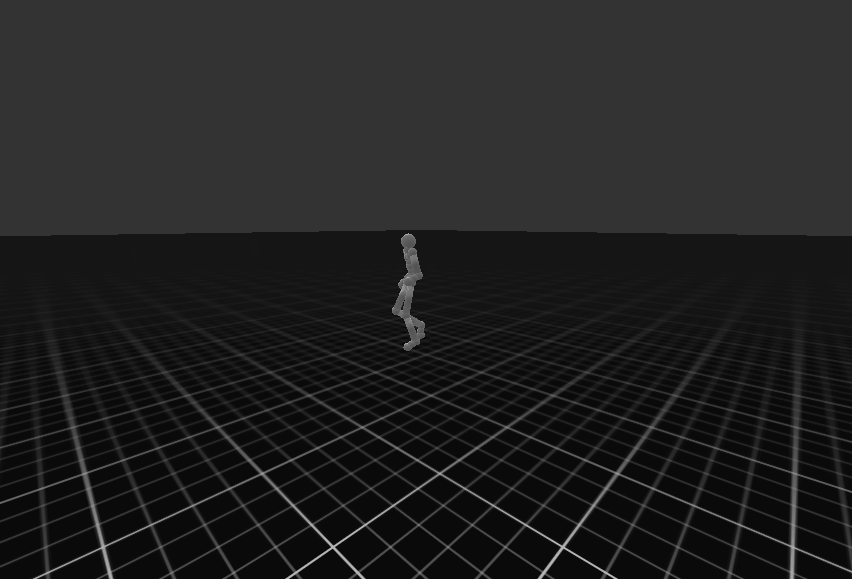 |  |
생각보다 제어 결과는 좋지 못한다. 이는 이전에 학습한 cvae loss 사이가 one order of magnitude를 따르지 않았으며, 이는 kl-loss가 reconstruction loss 비해 낮아 posterior collapse가 발생하였다. 예를 들어 데이터가 직진으로 갔닥 우회하는 데이터가 없으면 방향 틀기와 같은 제어는 불가능하다는 것이다. (stochastic 하다는 의미이다)
저자가 데이터를 공개하지 않았지만, 원 논문의 Fig 5.를 확인하면 사용한 데이터의 경로가 나온다. 보면 Path follower 환경에 맞는 데이터를 넣은 모양이고 급격하게 돌아오는 acyclic한 모션들이 많이 들어간 모양이다. 저자도 이러한 점을 아는지 한계에 부가 설명을 넣은 듯 싶다.
Code
코드는 최대한 정리해서 아래 리포지터리에 남겨놓았다.
- Authors

- Name
- Amelia Young
- GitHub
- @ameliacode