- Published on
고급컴퓨터그래픽스 | Deep Control & Synthesis
강의 상에서는 Control을 마지막 부분에 다루고 중간에 Synthesis를 한 번 다룬 적이 있었다. 하지만 마지막에 한꺼번에 넣는게 좋을 것 같아서 정리해보았다..!
Deep Motion Synthesis
Motion synthesis에서 다룰 내용은
- 물리 시뮬레이션 없이
- 모션 데이터를 deep neural network 으로 학습
- natural transition
주어진 모션 데이터로 별도의 transition 정보없이 character를 control 하거나 과거 모션 데이터를 통해 앞으로의 모션을 예측 (motion prediction) 혹은 특정 스타일을 입히는 style transfer, 모션을 음악에 맞춰 춤추는 sound to motion, Motion retargeting, Motion denoising이 있다.
모션 분야에 있어서 가장 많이 사용되는 deep learning 방법으로는
- Generative Model: VAE, Normalizing Flow, GAN, Diffusion
- Reinforcement Learning
물리 기반만 아니면 supervising method도 가능하다. ∵ 물리 시뮬레이션 값들은 stochastic하지 않기 때문.
잠깐 머신러닝 기법에 대해 설명하면,
Supervising learning
주어진 label의 데이터들로 훈련하는 특징이 있다.
Classification: 이산적 데이터를 예측하는데 사용
Regression: 연속적 데이터를 예측하는 사용
Feed-forward nerual networks: 현재 프레임의 포즈를 입력값으로 다음 프레임의 포즈 예측시 활용된다.
Convolution neural networks: 모션 시퀀스를 입력으로 전체 모션 시퀀스를 출력한다. 이 때 모션 데이터는 time-series로, 이미지와 달리 1D convolution feature map으로 활용된다.
Recurrent neural network: time series 데이터인 모션 데이터에 적합하며, 대표적으로 LSTM, GRU가 있다. 현재 프레임의 포즈를 입력으로 다음 프레임의 포즈를 예측한다.
여기서 언급한 것들은 보통 regression에 해당하며, 모션 데이터의 경우 라벨화는 여전히 사람의 개입이 필요하다.
Unsupervising learning
라벨이 없을 경우 데이터를 군집화하여 특정 집단으로써 데이터를 유추한다. 대표적으로는 clustering, dimension reduction이 있다.
그래서 다형체(manifold)의 형태로 훈련을 하게 되는데, 여기서 다형체는 topological space로 euclidean space와 국소적으로 닮아 있는데, 쉽게 설명하자면, 주변의 데이터들이 어떤 것이 있는지, 잘 보여주는 공간이라고 생각하면 된다. 연속적인 데이터(고차원)를 저차원으로 연속적으로 표현해낸 것이 다형체이다.
Autoencoder
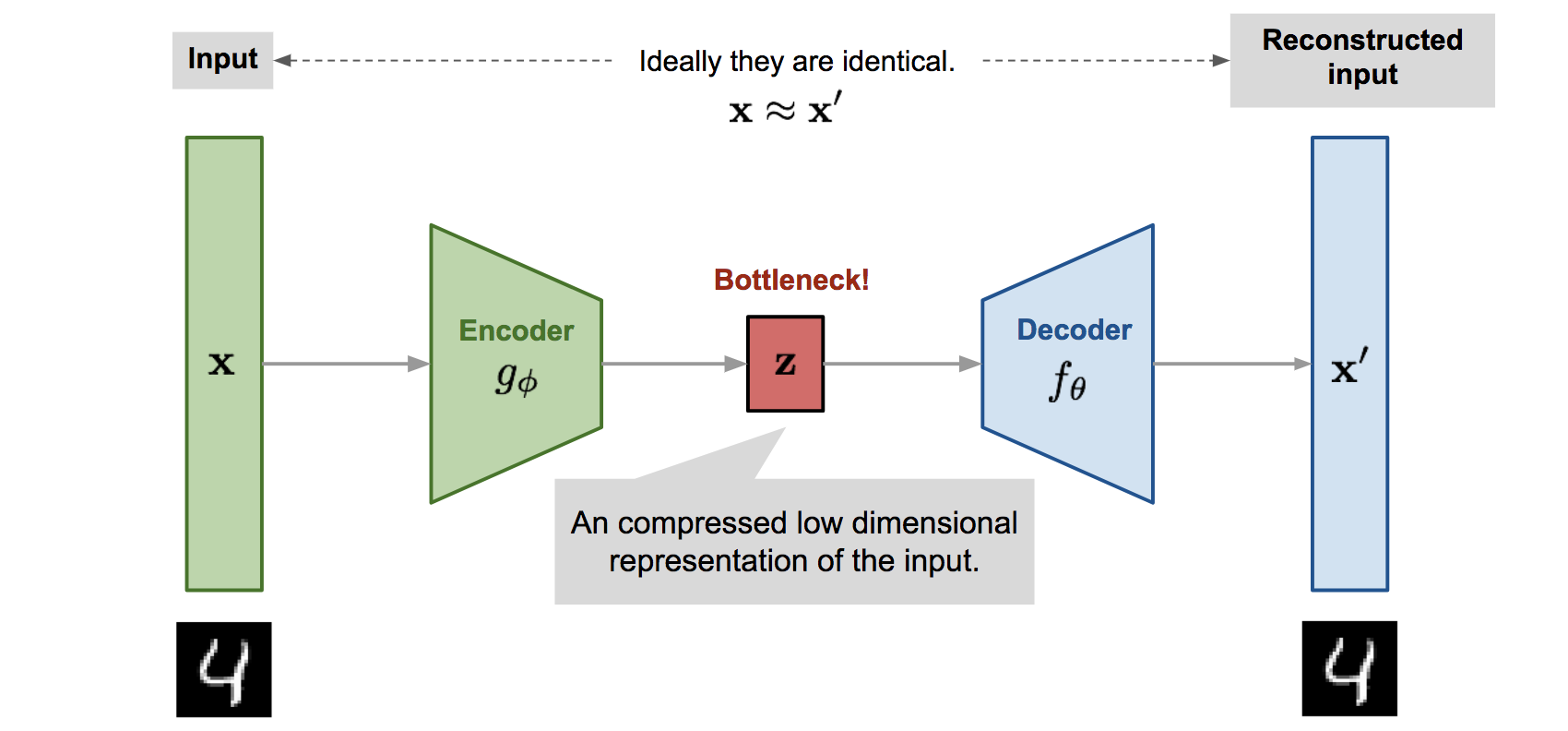
이미지에서 보이는 것과 같이 오토인코더로 저차원의 형태의 z space를 통해 reconstruction을 거친다. 오토인코더는 denoise에서 활용이 되고 특히 이러한 구조는 latent space = manifold로 활용되어 reconstruction로 근처 latent vector을 통해 모션 합성이 가능하다.
Reinforcement Learning
물리기반 motion control시에 자주 쓰인다. 물론 kinematic 기반에서도 활용된다. 최대한의 보상을 받으며 행동에 대한 강화를 하는 것이 핵심이다. 이와 관련된 내용은 Deep control에서 다뤄보겠다.
Generative Model
판별 모델(Discriminative Model)은 supervising method에서 훈련된 결과라고 보아도 무방하다. 반면 생성 모델은 샘플 기반으로 관측 확률을 추정하여 노이즈와 함께 샘플링이 된다. 따라서 생성 모델의 핵심은 어떤 데이터의 분포를 최대한 흉내내어 모델에서 샘플링한 것이 마치 데이터에서 뽑은 것과 같이 샘플을 생성해 낼 수 있다는 것이다.

생성 모델은 특이하게 판별 모델처럼 분류가 가능한데, Bayes' Theorem을 활용하면 Naive Bayes classifier로 분류가 가능하다. 생성 모델에서 분류하는 classifier로 Linear discriminant analysis (LDA)가 있다.
생성 모델의 대표적인 종류로는 아래와 같다.
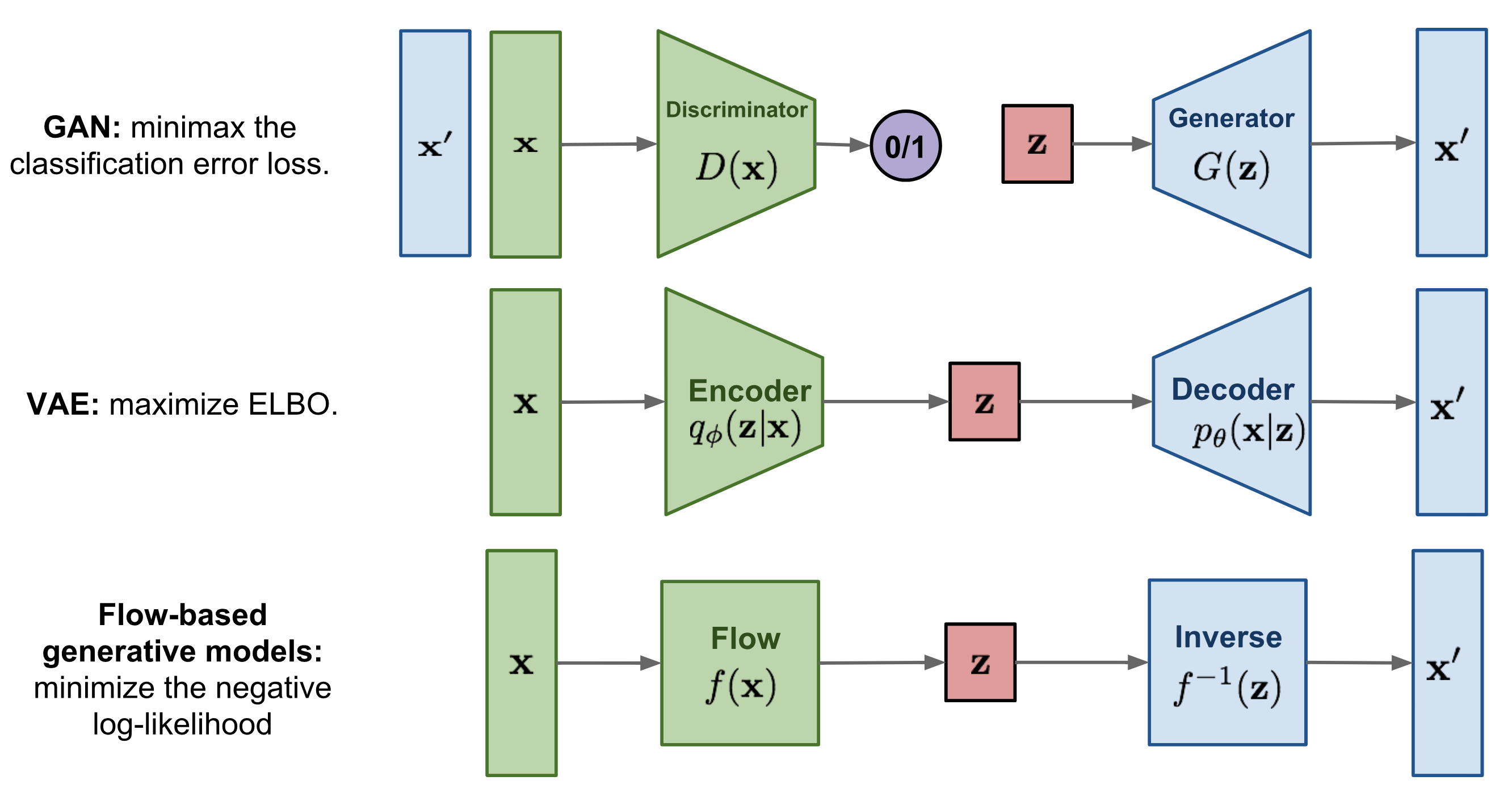
생성 모델이 모션 생성에 있어서 판별 모델보다 적합한 이유는 모션 자체가 확실하게 구분 지어서 분류가 될 수 있는 데이터가 아닌 부분도 있다.
Input & Output for Neural Network
위에서 기술되어 있듯 모션관련 해서는 보통 input, output는 아래와 같다.
- Input: current pose at frame i, or past/future trajectory, action type, contact label, sound data efc.
- Output: next pose at frame i+1 ➡ 정확한 skeletal pose를 요함.
데이터에 대한 디테일은 생각보다 이미지 훈련보다 더 많이 들어가는데,
- root frame에서 나온 local한 joint들의 정보인지
- root frame에서 수직축에서 회전 성분을 3d로 표현한지, 지면으로 projected된 2d 정보인지,
- euler angle: gimbal lock문제와 discontinuity 문제로 잘 사용되지는 않는다.
- rotation vector: discontinuity 문제
- unit quaternion: antipodal equivalance 문제(q=-q 같은 rotation으로 취급되는 문제)
- rotation matrix: redundancy가 큰 문제(too much data)로 6D representation인 Gram-Schmidt orthogonalization을 활용한다.
Training Data
논문에서 보통 아래와 같은 데이터를 많이 활용한다. 이 밖에도 rellusion이나 open pose로 3d reconsturction한 데이터를 쓰는 등 매우 다양하다.
Deep Control Policy for Character Control
위 내용의 경우 대부분 kinematic한 결과가 주였다면 이 section에서는 물리 기반 제어에 대해서 알아볼 것이다.
보통 물리 기반 모션에서는 physics simulation에서 거쳐간 결과를 보여준다. 쉽게 말하면 캐릭터가 중력의 영향을 받고 있을 때 단순히 joint position 정보만 보여준다면, 해당 캐릭터는 누더기 인형(rag-doll)처럼 풀썩 주저 않을 것이다.
물리 기반 캐릭터 시뮬레이션의 문제점으로는
- 데이터를 기반으로 어떻게 캐릭터들의 모션을 수행할 수 있는가?
- 데이터 없이 수행이 가능한가?
- 특정 task에 잘 수행할 수 있는가?
- 골격근 시뮬레이션
- 비인간(동물과 같은) 캐릭터에서의 적용
다시 돌아와서 강화학습에 대해 짧게 살펴보자
Reinforcement Learning
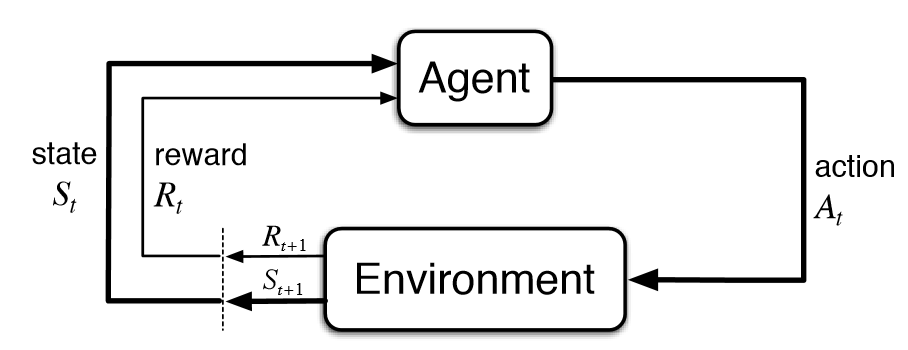
도표에서 볼 수 있듯, 환경에서 지속적으로 정보를 습득하고, 정보를 기반하여 agent가 더 많은 보상을 얻을 수 있는 행동을 취하게 된다.
포스트에서는 강화학습과 관련해서는 깊게 다루지 않을 것이다. *간략하게 요소들에 대해서만 정리함.
- State: environment의 상태
- Observation: state의 부분집합이다. 보통 agent 입장에서 관측한 결과로도 해석할 수 있다.
- Action space
- Discrete action space: 위 아래와 같은 이산적인 행동을 의미
- Continuous action space: joint torque과 같이 실수값과 같은 데이터가 포함된다.
- Policy: agent의 뇌라고 역할이라고 봐도 무방하다. 도표에 들어가는 agent 부분에 policy가 있다. 굳이 구분 짓자면, 환경에서 행동하는 주체는 agent고, action space와 같이 결정하는 주체가 policy이다.
- Deterministic policy: action space가 discrete한 경우
- Stochastic policy: 결과값이 확률분포인 경우, 가능한 action들을 output으로
- Categorical policy: action space가 discrete한 경우
- Diagonal Gaussian policy: action space가 continuous한 경우. Multivariate Gaussian distribution의 경우 mean vector & covariance matrix로 묘사된다. 특이하게 diagonal gaussian distribution은 유일하게 entries가 대각선으로 covariance matrix의 표현된다. 후에 이를 벡터로 표현할 수 있다.
Diagonal Gaussian Policy
항상 mean action과 observation이 맵핑되는 neural network가 있다.
Covariance matrix이 다음과 같이 표현이 되는데,

여기서 주의할 점은,표준 편차가 로그 형태로 나온다는 것이다. 이런 식으로 표현이 되면 표준 편차가 nonnegative 형태로 표현이 되는데 로그 형태는 자유롭게 입력값을 받을 수 있기 때문이다. 그리고 굳이 훈련시에 하나하나 신경쓰지 않아도 되는 이점이 있다. 또한, 지수함수로 계산이 되면 표준 편차값을 손실 없이 얻을 수 있기 때문에 여러모로 이러한 표현이 쓰인다.
Stochastic Policy
다시 돌아와서 stochastic policy는 훈련 시간에 매 step마다 분포도에 의해 action이 샘플링된다.
예측 시에는 가장 높은 확률의 action을 선택하거나(categorical policy) 혹은 mean value로 선택한다(diagonal gaussian policy).
Policy
결론적으로 정책(policy)이라 함은, deep neural network로 사용된다. 그래서 보통 논문이나 글에서 정책을 로 표현하는데, 쉽게 말해, 주어진 상태가 있을 때 action을 출력한다라고 이해하면 된다.
Episode
논문에서 Rollout, trajectory로 불린다.
상태와 행동의 연속 시퀀스로 나타내어지는데, 첫 상태의 경우 state-state distrbution()에 의해 임의로 샘플링된다.
state transition은 주로 환경과 최근 행동에 의해 좌우된다. 혹은 와 같이 deterministic하게 계산되어지거나 처럼 stochastic하게 계산된다.
Reward
보상의 경우현재 상태와 행동을 취했을 때 다음 상태 모두 영향을 받는다(). 현재 상태만(), 혹은 현재 상태와 행동 둘다 입력값으로 들어가는 경우도 있다().
보상은 모두 누적되어서 각 episode에 저장이되는데, 특정 time step까지 각 에피소드마다 훈련시키거나 혹은 무한으로 훈련시켜 감가율(discount-factor)를 적용하는 경우도 있다.
근데 여기서 discount factor을 왜 적용시키냐?는 의문이 있을텐데, 무한정으로 더하는 건 계산하기에는 어려움이 있기 때문이다(may nor converge to a finite value, and is hard to deal with in equations).
Goal of RL
궁극적으로는 강화학습은 최대 보상을 극대화하는 정책을 찾는 것이 목표다

Value functions
state 혹은 state-action pair의 가치를 알면 유용하다.
여기서 가치(value)는 특정 state나 state-action pair에서 시작했을 때의 기댓값이다.
대부분 강화학습에서 사용되며
state의 value function은
state-action pair의 value function은
On Policy Value Function
- On Policy Action-Value Function
- Optimal Value Function
- Optimal Action-Value Function
만약에 Optimal action-value function을 알고 있다면, 행동은 아래와 같이 구할 수 직접적으로 계산이 되어진다.
가끔 아래와 같이 혼용되어서 표현되곤 한다.
Bellman Equations
위 4가지 value function들은 bellman equation에 따른다.
벨만 방정식의 기저 아이디어는: 시작점의 가치는 다음 도달할 지점에 대한 보상 + 다음 상태
그래서 각각의 equation에 대한 벨만 방정식은
- On-policy value functions on bellman equations
- Optimal value functions on bellman equations
Advantage Functions
강화학습에서 행동이 절대적으로 좋은지에 대해 필요없고, 단지 평균에서 최상의 행동인지 알고 싶을 때가 있따.
이 때 상대적으로 행동에 대한 이점이 있는지 확인하기 위해 advantage function을 활용한다.
RL Algorithms
- Classic tabular RL methods: Dynamic programming (value iteration, policy iteration), Monte Carlo method, Temporal difference method, SALSA, Tabular Q-learning
- Deep RL methods:
- Policy gradient: REINFORCE, A3C, TRPO, PPO
- Q-Learning: DQN
- Combination: DDPG, SAC
다양한 알고리즘은 아래와 같다.

Wrapup & Conclusion
여기까지가 강의의 끝이다. 사실 로보틱스와 나름 많이 연관되어 있다고 생각한다. 강화학습을 한 번 쭈욱 훑어보면서 왜 이런걸 썼지에 대한 의문이 조금이나마 해소된 것 같아서 기쁘다 ㅎㅎ..
Project 4 - Reinforcement Learning
사실 이것도 TDD 안했는데 대충 몇가지 테스트한 걸로 했다고 발표했었던 것이 기억난다...ㅠㅠ 아무리 생각해도 뭘 TDD 하라는 건지 모르겠다. 원래 기존 프로젝트에서 연결을 해야하는데, 이 때 아마 너무 지쳐서 그런거 신경 안쓰고 pybullet이랑 연결시켜서 아래와 같은 hopper 환경을 만들었다.

목표는 1000m x축 방향으로 쭉 가는 거고 아마 훈련하는데 소요된 시간은 1일이었던 걸로 기억한다.


여기까지 정주행해주셔서 감사합니다. 😘
- Authors

- Name
- Amelia Young
- GitHub
- @ameliacode