- Published on
REVIEW | A Deep Learning Framework for Character Motion Synthesis and Editing
Review Today
오늘은 저번 시간에 다룬 논문의 후속 연구에 대한 논문이다.
2016년 논문인만큼 막 Neural Network 관련 활용 연구가 활발히 할 때인 만큼 related works를 보면 그래프를 이용한 연구들을 소개한 점이 흥미롭다. 요즘이야 뭐 거의 Data-driven method만 소개되는 거에 비하면 흥미롭다 ㅎㅎ
Introduction
이번 시간에 다룰 논문은 Animation synthesis, 모션 합성과 이에 기반한 editing 을 deep learning framework 방법을 소개한다. Convolutional AutoEncoder에 방대한 모션 데이터를 입력을 받는다. 이 때 stack된 feedforward neural network을 통해 motion manifold의 low level 정보를 human motion의 high level parameter를 맵핑한다. 이는 새로운 motion sequence를 생성해낸다. feed forward control network와 motion manifold network은 각각 독립적으로 훈련된다.
저번 논문에 나온 이 motion manifold(=latent space, low level space)은 convolutional autoencoder의 hidden unit으로 표현되고 모션의 광활하고, 연속적인 정보를 담는다.이러한 정보를 토대로 Gram matrices를 통한 방법으로 스타일을 합성하는 등이 있는데, 본 논문에서는 neural network로 해결한다- 라고 보면 될 것 같다.
Related works
Kernel-based Methods for Motion Blending
kernel의 역할은 서로 다른 양상의 데이터의 유사도를 계산하여 분류하는 classifier이다. non-linear problem을 linear로 해결하는 방법 중 하나이다.
- Radial Basis Function
- RBF + inverse kinematics
- RBF + dynamic time warping: to align timeline
RBF 방법들은 노이즈나 변화 대응에 취약하기 때문에 overfitting 문제가 생긴다.
- Gaussian Process (GP)
- Gausian Process Latent Variable Model
이러한 방법들은 메모리적이로 비효율적인 cost를 낳는 한계점이 존재한다.
Interactive Character Control
- Motion Graph: 대용량 motion 데이터에서 transition 잘 보여주나, 존재하는 데이터"만" 재생한다.
다른 종류의 데이터와 다른 시간대의 있는 데이터를 합성하기가 쉬운 일은 아닌데, 이를 기준을 놓고 정하는 건 확실히 전체 performance와 정확성에 직결되며 병목현상이 될 수 있다.
동일 시간대에 가장 좋은 action을 찾는 방법으로 강화학습을 적용하는 시도도 있었다.
- motion fields
Deep learning for Motion Data
딥러닝은 데이터셋의 특징을 자동적으로 학습하는 강점이 있다. 본 논문에서는 모션을 따로 분류하지 않고도 이러한 이점을 이용하겠다고 서술한다.
- RNN
- Convolutional Autoencoder
- cRBM
- ERD: 첫 프레임부터 전체 모션을 통합하도록(time-series) 계산이 되는데, 애니메이터 입장에서는 전체 시퀀스에서 부분적인 편집하기(procedural)를 원하므로 이러한 방법은 애니메이터에게 적합하지 않다고 한다. 아마 개인적인 생각이지만, 본 논문에서는 독립적으로 단계별로 훈련을 하게 되는데, 이점을 강조한듯 싶다.
System Overview

각 단계는 독립적으로 훈련된다.
- Motion Editing: motion 데이터에서 hidden unit convolutional encoder를 통해 훈련한다.
- Motion Synthesis: hidden unit 토대로 feedforward neural network을 통해 high level control parameter으로 맵핑된다.
- Disambiguation: high level parameter들을 feedforward network를 통해 trajectory를 통해 editing을 가능케하고, 속도 또한 조절이 가능하다.
Data Acquisition
- CMU dataset: 120fps
- 자체적으로 녹화한 mocap data
데이터 포맷은 예전 MotionVAE 전처리할 때 한 방법과 동일한 것 같다. 당시 PFNN(2017) 논문 참고해서 만들었는데 동일한 것 같다.
joint 위치들은 root(pelvis, hip 등등)를 origin으로 두고 local하게 계산되는데, shoulder joint position과 hip joint position에 기반하여 forward direction을 계산한다. 자세한 전처리 방법은 논문 참고*
간단한 고등학교 기하와 벡터 수준이라, 코드 보면서 비교하면 크게 어렵지 않다.
120 frame을 overlapping window로 감안해서 총 240 frame으로, joint의 총 자유도는 70(20joints * 3, forward direction(3), root velocity(3), foot contact(4))으로 아래와 같이 input data를 정의한다.
1. Building the Motion Manifold (=Motion Editing)
위 그림에서 볼 수 있는 것처럼 Hidden unit으로 그래프에 나타진 다형체가 Motion manifold인데, 이 범위 내에 있는 motion의 정보가 valid motion으로 간주한다.
이전 연구와 동일하다. single layer of encoding을 사용하는 이유는 multliple layer of pooling/de-pooling할 경우 reconstruction이 blur한 결과를 낳기 때문이다.
Encoder
아래는 encoding식. 는 max pooling. weight (), bias,
Decoder
전과는 다른 점은 activation function을 non-linear한 RELU로 대체한 점이 있다. parameter는 실험 결과로 이러한 점이 나았다- 란 내용만 있어서 이에 관해서는 딱히 설명할 부분은 없는 것 같다. backward operation은 아래와 같다.
inverse pooling operation()일 때 hidden unit을 두 개의 unit을 visible layer에 전달해야하는데, 이 경우 invertible 하지 않으며 approximation을 반드시 거쳐야한다. 일때 visible unit 상응하는 두 개를 random 하게 고르고 그 중 값을 할당하고 나머지는 0으로 설정하면서 훈련한다. 하지만 maximum operation으로는 noise를 야기하므로 average pooling operation으로 hidden unit의 값들을 균등하게 확산하게 한다.
아래는 cost function
cost function은 실질적인 값과 생산된 값의 차의 제곱과 sparsity term으로 이루어진다.
sparsity term은 적은 수의 parameter를 사용하게끔 보장한다. cost function을 최소화하기 위해 stochastic gradient descent 방법을 이용하였고 X값은 random하게 input된다. Adaptive Gradient descent algorithm으로 Adam을 이용하였으며 overfitting을 피하기 위해 dropout을 하였다.
훈련시간은 총 6시간.
논문에 있는 convolutional filter관련 그림 (Figure 3)를 보면, 가로축(시간)에 따라 각 joint들의 자유도(세로)가 연결된 형태를 보면 연속적이고 연관성이 높음을 알 수 있다.
요약하자면 이 단계에서는 모션 데이터베이스를 입력으로 Convolutional autoencoder를 통과하여 motion manifold(=low level, dimensional)로 훈련한다.
2. Mapping High Level Parameters to Human Motions (=Motion Synthesis)
다음 단계는 hidden unit을 토대로 high level parameter을 맵핑하는 단계이다. 코드를 뜯어보니까 간단히 말해, 위에서 훈련된 Manifold(그래프와 같은..)에 다가 정규화된 motion data → encoded된 결과를 regression하는 것 같다.
여기서 high level parameter는 abstract parameter로 지형에 투사된 root trajectory나 end effector의 trajectory를 표현한다. 하지만 high level parameter로 locomotion task를 수행하기 쉽지 않은데, 이는 결과물에 대한 ambiguity와 multi-modality 문제 때문이다. 예를 들어 다양한 valid 모션들 중 일직선으로 걷는다고 가정하면, 보폭은 일정하지 않거나 동일한 trajectory여도 sync가 맞지 않은 문제가 존재하는데, 이를 모호하게 합성하면, 둥둥 떠다니는 것처럼 보이는 문제가 발생한다. 이를 universal하게 풀 수 있는 방법은 없으므로 본 논문에서는 individual하게 나뉘어서 해결한다.
Structure and Training of the Feedforward Network
위의 단계와 유사하지만 세 개의 layer가 추가된 모습이다. 는 ambiguity 문제를 해결하기 위한 task-specific operation이다. 자세한 파라미터는 논문 참고*
high level parameter과 output motion 사이 regression 훈련을 위해 아래와 같은 cost function
다시 말해, 이 단계에서는 high level parameter와 저차원의 motion manifold를 비슷한 프로세스이나 세 개의 레이어를 통과하여 맵핑하게끔 훈련한다.
아래는 cost function을 통해 최소화하는 방향으로 훈련. 위와 cost function과 동일하다. 훈련할 때 X값은 locomotion에 해당하는 모션 데이터'만' 넣어서 훈련. (위에서 언급된 ambiguity한 문제로 universal하게 풀지 못하기 때문에 task-specific으로 문제 축소.)
이에 영향으로 총 훈련시간은 1시간.
※ 근데 코드에서는 훈련 끝나고 난 후 데모로 통합할 때만 저렇게 통합하지, 훈련할 때는 아예 trajectory 정보+end effector 정보 = high level parameter?와 hidden unit 이 둘만 가지고 맵핑한다.
3. Disambiguation for Locomotion (=Disambiguation)
Disambiguation에서의 문제점 중 하나인 feet contact 부분(둥둥 떠다니는 문제)을 해결하기 위해 아래와 같은 정보가 들어간다. 여기서 T는 위와 다르게 trajectory, foward facing direction의 경로라고 보면 된다.
위에 ambiguity 문제를 해결하기 위해 다음과 같은 function이 들어갔는데, F는 high level parameter를 기반하여 두 발의 heel과 toes들의 contact duration을 square wave를 계산한다. 함수에 따라 계산되므로 -1~1의 값을 가지게 된다. 이 때 F에 계산된 파라미터들 들은:
- : frame별 angle의 summation으로 계산 되고 각 프레임별 값은 를 wavelength step로 나눈 값으로 계산된다. wavelength 인접한 off-to-on(발이 닿지 않는 부분부터 닿는 부분까지~) frames를 뺀 값을 토대로 전체를 평균으로 하여 4(left/right, heel/toe)에 적용된다. 이는 footstep frequency를 반영한다.
- : gait cycle에 기반하여 계산되는데, 아래와 같이 계산된다 와 는 각각 프레임별 발의 contact 횟수 이를 토대로 regression 훈련 시 이와 같은 input으로 들어간다.
아니 그럼 foot contact 정보는 어딨냐..? Data acquisation 부분에서 가장 마지막 4개의 정보가 각각의 foot contact 정보이다. 여기서는 이 정보를 사용해서 계산하였다. 이 부분은 timeline에 따라 하나의 array를 만들면 쉽게 이해할 듯 싶다.
자 이제 locomotion path(=trajectory)와 contact information을 regression하여 훈련시켜 보자!
마찬가지로 여기서 T는 trajectory. stochastic gradient descent를 통해 훈련된다. 결과적으로 trajectory를 입력으로 이 계산되고, 이에 따른 foot contact(F)를 계산하게 된다.
(개인적인 생각이지만, 적다보니 순서가 2,3랑이 뒤바뀐 것 같은 느낌이..)
Motion Editing in Hidden Unit Space
Constraint를 cost function으로 계산함으로써 feet skating를 방지하고, bone length 보존, 정확한 trajectory locomotion을 기대할 수 있다. 자세한 내용은 논문 참고*
- Positional Constraints
- Bone Length Constraints
- Trajectory Constraints
이렇게 계산된 값의 합의 최솟값을 motion manifold 계산하는 과정에서 backward operation(decoding)의 input값으로 들어가게 된다! 이래서 아예 제일 첫번째 단계를 Motion Editing 단계라고 박아둔 것 같다. 의문 해결!
Motion Stylization in Hidden Unit Space
이 부분은 모든 훈련과정이 끝나고 나서 원하는 모션의 스타일과 모션의 내용 두 개의 모션을 스타일화하는 과정이다. 논문에서의 style function은 cost function으로 훈련되는데, 이 떄 H는 초기값으로 노이즈(랜덤number..)를 주고 정의한다. 훈련된 결과는 decoder로 넘어가고 난 '후' 위 editing이 가능..하다고 한다.
Experimental Results
아래 이미지를 누르면 영상으로 이어진다.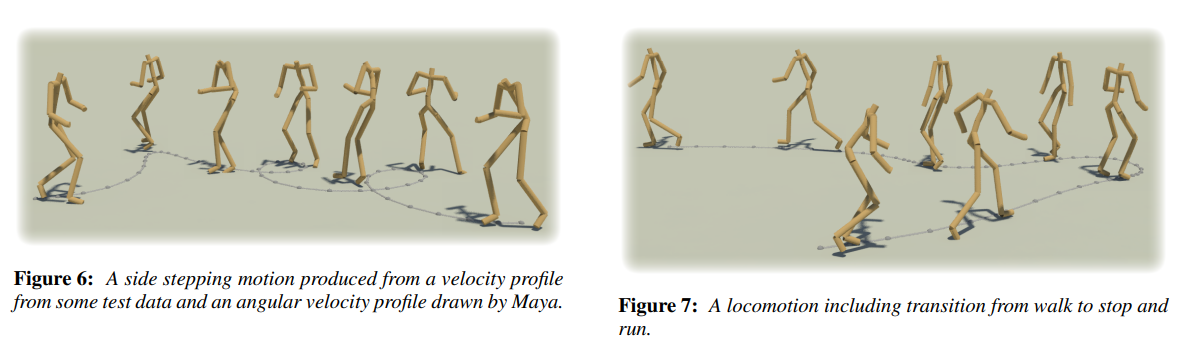
Conclusions & Limitations
실제 모션과 manifold를 거쳐서 맵핑된 high level parameter 간 ambiguity 문제는 여전히 남아 있다. 머신 러닝 input parameter에 좌우되는 ambiguity문제는 흔한 이슈라고 한다. multi-modality로 그에 상응하는 여러 데이터의 생성으로 sync가 맞지 않게되는데, 이를 평균값으로 모호하게 더해버리면 위에서 언급된 둥둥뜨는 오류가 나타나게 된다.추가적인 데이터(foot contact model)를 더 넣는 방식으로 해결될 수 있다고 한다.
multiple layer로 인해 depooling과정에서 motion이 모호해지는 문제로 인해 convolutional autoencoder는 single layer을 고수하고 있고, 추가적인 모델을 추가한 형태인데, 좀 더 단순하게 hypercolumn으로 해결하는 것을 기대한다고 서술한다.
Wrap up
사실 논문 읽으면서 고쳐지지 않은 버릇 중 하나가 너무 덤벙거리면서 읽는다는 거..ㅠㅠ ADHD탓하기 분명 이 논문을 3번은 읽은 것 같은데, 아는 건 알지만 의문을 가지지 않고 넘기는 경우가 많았던 것 같다. 다른 분의 세미나 영상을 보면서 그간 내가 발표한 논문 너...무... 덤벙거림이 눈에 아른..거리더라 ㅋㅋ ㅠ 막학기인데 많이 반성했고 앞으로 있을 디펜스나 학회 때 안일하게 준비하면 안되겠다는 나름의 다짐이 생겼다. 흑흑.. 암쏘스튜핏..😥
여튼 이 논문을 다시 정리하면
- Convolutional Autoencoder를 통해 Motion manifold(low level, dimensional) space를 훈련한다.
- 이를 토대로 root trajectory와 같은 정보가 포함된 high level parameter을 훈련한 manifold에 맵핑하는 단계를 거친다
- 맵핑하는 과정 중 disambiguation을 위해 추가적인 foot contact 정보를 통해 frequency와 contact을 계산하여 ambiguity 문제를 해소한다.
- Stylization은 별도?의 과정.
- 각각 3개의 모델을 훈련한 후, 하나의 프로세스로 통합할 때는 1 → 3 → 2 이렇게 거치는 것 같다. 뭔가 코드랑 논문이 인지부조하가 계속 오네 후..
- Authors

- Name
- Amelia Young
- GitHub
- @ameliacode