- Published on
REVIEW | A Survey on Reinforcement Learning Methods in Character Animation
Review Today
캐릭터 애니메이션 분야 중 DRL을 이용하여 정리한 논문이 많이 있지 않은 편인데, 올해 상반기에 Eurographics 2022에서 좋은 논문이 나왔다.
관련 논문으로 아래와 함께 읽으면 좋을 것 같아서 남긴다..!
- A Survey on Deep Learning for Skeleton-Based Human Animation: 관련 지식이 없다면 먼저 읽을 것을 추천한다. 스키밍 해봤는데, 기본적인 Quaternion과 같은 기본 내용들을 제공한다.
Introduction
Machine learning의 하위 분류 중
- Supervised Learning | conventional gradient-based optimal control
- Unsupervised Learning | conventional gradient-based optimal control
- Reinforcement Learning
으로 나뉠 수 있다. 어떤 특정 행동(controlled action)에 따른 환경에 의한 보상(reward)을 얻기 위한 method로 character animation control 분야에서는 Reinforcement learning을 주로 사용한다.
이 논문에서 다루는 분야는 character animation 분야 중 skeleton motion control 이며 Deep Reinforcement Learning를 활용에 대해 소개한다.
- individual motion skills
- motion planning
- crowd simulation
Problems in Character Animation
모션에서는 크게 skeleton이 어떤 행동(behavior)을 하는지, 다수의 skeleton 와는 어떤 상호작용(interaction)을 하는지에 포커스를 둔다. 따라서 어떤 행동에는 skeleton의 control을 고려해야 하며, skeleton간 상호작용은 motion planning 즉, scene에 어떤 곳에 position이 되어야 하는지 관건이다.
- Behavior = Skeleton Animation
- Interaction = Character Motion Planning
Definitions and Preliminaries
Reinforcement learning은 markov decision process에 기반한다.
강화학습 기본 개념은 논문에 친절히 설명이 되어 있으니 넘어간다! 이 부분에 대한 설명이 필요하면, 추가적으로 포스팅을 해보겠다.
대략적으로 RL의 episode는 아래와 같은 순서로 돌아간다.
- initial state = reset()
- action = policy(state): policy as MDP, optimal policy state일 때의 action을 구하는 것이므로 조건적이다.
- obs + reward + done = step(action): 보통 obs+reward+done = state라고 보거나 혹은 observation을 state라고 두는 경우가 있다.
- if done, reset: 1로 다시 돌아간다.
모든 상황을 다 관측이 불가능하니 보통 Partial Observable Markov Decision Process 를 사용한다.
Multi agent인 경우에는?
single agent와는 비슷하지만, 다수의 agent이라는 점에서 Partially Observable Stochastic Game 을 기반으로 하고 있다. Reward를 공유하는 Decentralized MDP를 사용하는 경우가 있지만, 이는 보상이 한정적인 zero sum game일 경우 활용하기가 어려운 단점을 지니고 있다. 개인(single agent scenario) Reward로 적용하면 위의 POMDP로 전환이 가능하다.
다른 대안으로는 Agent Environment Cycle Game 이 있는데, 다른 formulation과 다르게 다음 agent를 결정하는 next agent function이 있다. 특이하게 이전 방법과는 다르게 environment 자체도 하나의 agent로 정의된다. 서로 공유된 state에서 개별 action space를 취한다는 점도 여기서 눈겨야 봐야할 점이다.
Environment design
- Observation space
- Action space
- Reward function
Fundamentals of RL Algorithms

- Policy Gradient Theorem: action을 결정하는 policy function optimize | trajectory의 총 보상을 이용하여 optimzation target의 gradient를 구하게 된다. 따라서 주어진 보상에 따라 Policy를 직접적으로 훈련한다.
- Bellman Equation: 기대하는 action들을 learn | Value function을 이용하며, 상태에 대한 즉각적인 보상과 감가된 상태를 더한 값이 곧 상태의 가치로 정의되어 계산된다. 따라서 state에서 가장 최선의 action을 토대로 policy를 훈련하게 된다.
이 둘의 가장 큰 차이점은 Policy gradient는 trajectory 당 reward를, bellman equation은 state와 action에서의 reward 계산하는데 있어서, 후자는 state distribution 적용으로 policy performance의 통계에 의존하는 경향이 있다.
Reward Hypothesis, Discounting, Advantage
강화학습에서의 전반적인 목표는 보상의 누적합을 극대화하여 Agent로 하여금 이상적인 행동을 하게끔 유도하는 데 이를, Reward Hypothesis라고 한다. 여기서 Discount factor(감가율)은 훈련에 있어서 총 보상을 최적화하며(improve training by optimize total reward), Policy gradient에서 구한 gradient estimation의 분산을 감소시키기 위해 Advantage를 부여하게 된다. Action의 가치를 부여함으로써 더 효율적인 훈련을 기대할 수 있으며 Advantage는 아래와 같이 q function value function의 차로 보통 계산하게 된다.
Classification of RL ALgorithms

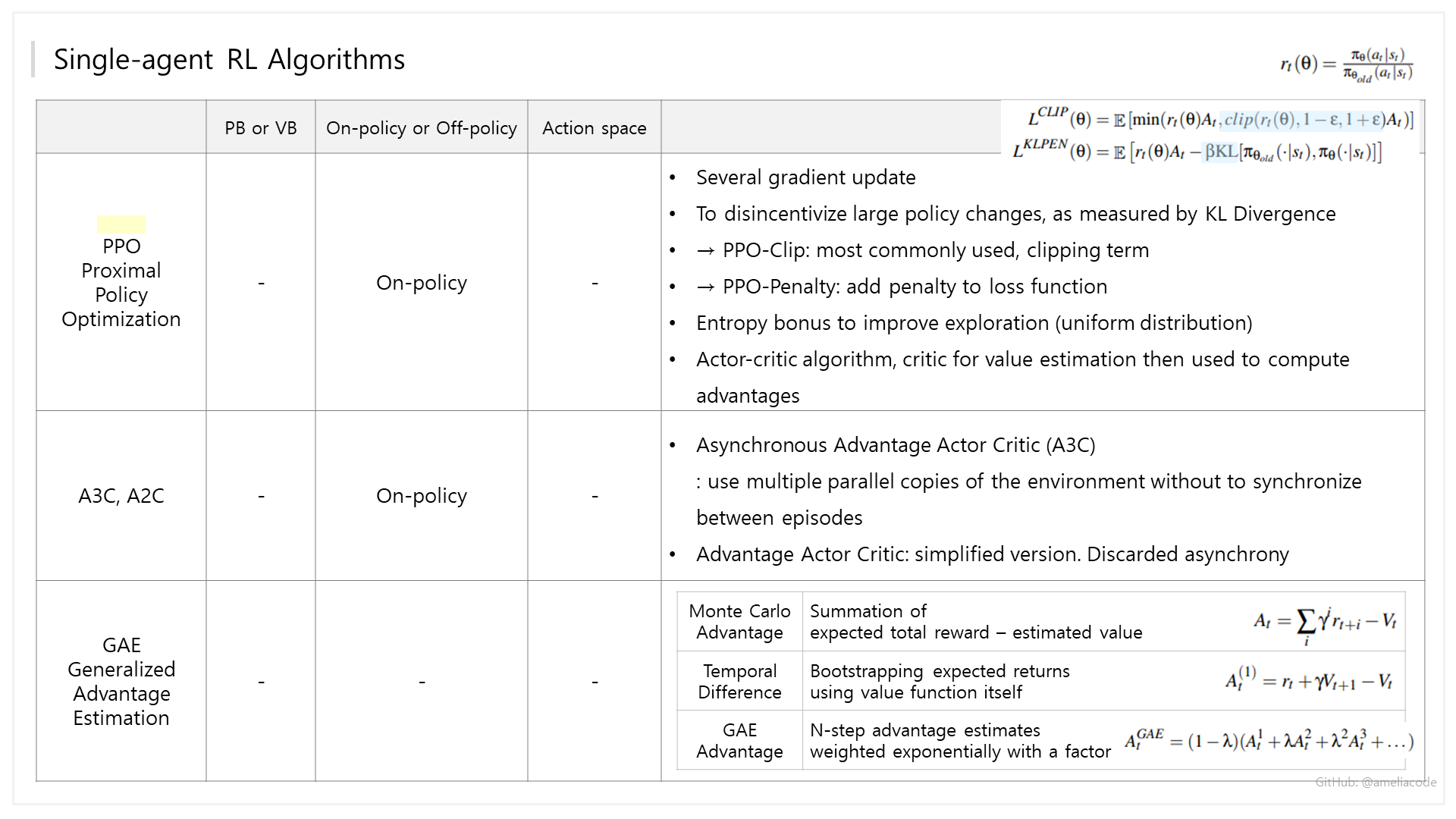
Single-agent RL Algorithms


Multi-agent RL Algorithms



Skeletal Animation



Crowd animation
보통의 환경은 정적으로 간주하는데, 군중 애니메이션의 환경은 동적이다. 그래서 Holonomic 하다고 해서, 움직일 수 있는 자유도 = 총 자유도인 cartesian control을 통해 motion을 컨트롤 한다. Performance measure이라고 해서 동적 환경에선 목표 지향적인 performance가 어렵다는 점과, 조금더 사실적인 움직임을 위해 어떤 actuator을 써서 자연스러운 결과를 도출할지가 군중 애니메이션의 도전과제라고 보면 좋을 것 같다.
이 부분은 개념보다 Application의 위주에 관한 내용으로 생략! 요약하자면 군중 애니메이션에서 PPO를 사용하였고, 공통된 문제는 collision avoidance가 있었다.
※ 내 분야가 군중 시뮬레이션이 아니라서 잘 이해하지 못하였다. Multi-agent RL 문제인 것만 이해하였다..ㅠㅠ
Human Interaction
공유된 환경에서 상호작용하는 agent는 Theory of mind 개념을 기반으로 한다고 한다. 요약을 하면 어떠한 상태를 통해 그 행동을 유츄하는 것을 의미하는데, 이 개념 그대로 강화학습에 적용하여 전체적인 환경/다른 agent의 행동을 관측하는 것이 model based approach가 적합하다고 한다.
Frameworks
아래는 최근 DRL 연구에서 많이 쓰이는 framework다. 개인적으로 새로 나온 Isaac gym은 parallel environment에서 훈련이 가능해서 시간적으로 절약이 가능하다는 장점이 있다. Pybullet은 documentation이 잘 되어 있으나, 중구난방 같은 느낌이 없잖아 있다.
| Categories | Detail |
|---|---|
| Environments | Gym: single agent, RLLib: single agent & multi agent, Petting Zoo: multi agent |
| Physics Engine | Mujoco, Pybullet, Dart, Nvidia Isaac Gym, ML-Agents(Plugin for Unity, Crowd Simulation), Osim(Based on OpenSim, Biomechanics, Neuroscience), Nimble |
| Neural Networks | Tensorflow, Tensorflow2(Keras), Pytorch, Jax |
| Algorithms & implementation | OpenAI Baselines(deprecated), Stable Baselines(2-Tensorflow, 3-Pytorch), RLLib(Ray Library), ClearRL(Pytorch), Dopamine: easy experiment, flexible development, TF-agents(Tensorflow), Tianshou(Pytorch), Rlax(Jax), +d3rlpy, d4rl_pybullet(online learning, offline learning) |
- Authors

- Name
- Amelia Young
- GitHub
- @ameliacode