- Published on
📖 STUDY 만들면서 배우는 생성형 AI | 생성적 적대 신경망
Generative Adversarial Network
이하 GAN은 생성자와 판별자 간의 trade off로 데이터를 생성한다. 이 때 생성자는 노이즈에서 원본을 샘플링한 것과 같이 샘플을 변환하며, 판별자는 생성자의 위조품인지를 예측한다. 전체적으로 생성자는 샘플을 생성해내고, 판별자는 진위여부를 판별하게 되는데, 훈련이 거듭할 수록 생성자는 판별자를 속일 새로운 방법을 찾게 된다.
책에서 나온 GAN의 유형은 아래와 같다.
- Deep Convolutional GAN
- WGAN
- CGAN
DCGAN
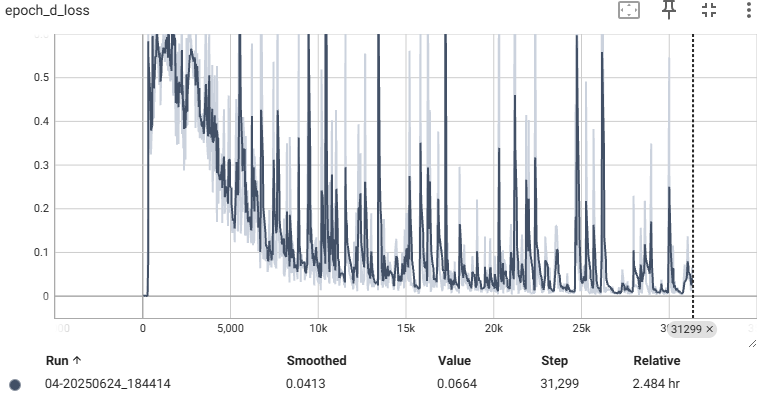
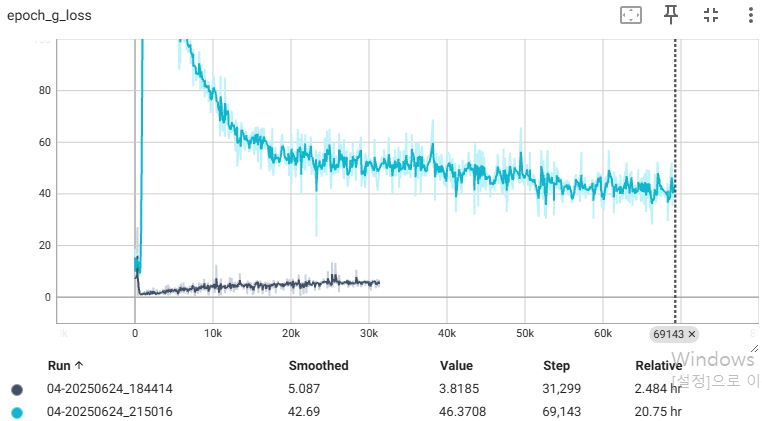
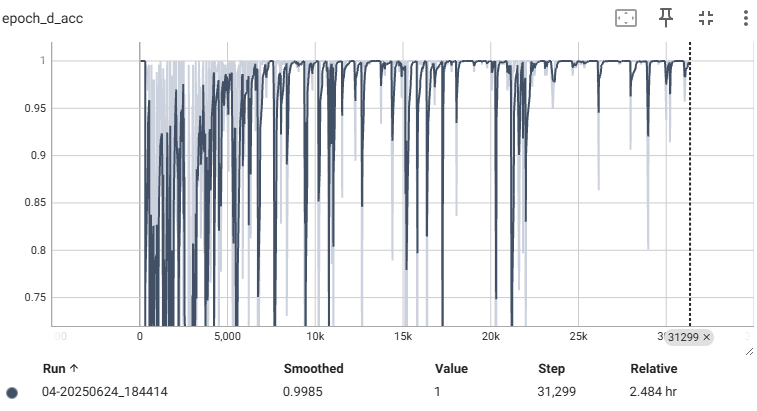
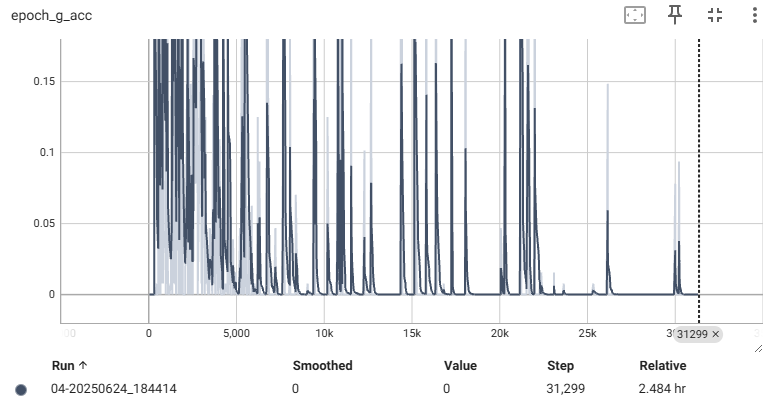
생성된 이미지는 이미지 사이 거리(L1 norm)로 유사한 샘플을 보여준다.
GAN 훈련 팁과 트릭
판별자가 생성자보다 뛰어난 경우
판별자가 강하면 손실함수 신호가 약해져 진짜와 가짜를 완벽하게 구분하고 그래디언트가 사라져 학습이 이루어지지 않을 수 있다. 생성자가 향상되지 않기 때문에 판별자를 약화시킴
- 판별자 Dropout층의 rate 매개변수 증가 ➡️ 네트워크를 통해 흐르는 정보양 줄임
- 판별자의 학습률을 줄임
- 판별자의 합성곱 필터 수를 줄임
- 판별자를 훈련할 때 레이블에 잡음 추가
- 판별자 훈련 시 일부 이미지 레이블을 무작위로 뒤집음
생성자가 판별자보다 뛰어난 경우: mode collapse
mode = 판별자를 항상 속이는 하나의 샘플 mode만으로 판별자를 쉽게 속이므로 생성자 입장에서는 다양한 출력의 필요성이 없다.
유용하지 않은 손실
생성자의 손실과 이미지 품질로 이루어지지 않을 수 있다. 생성자의 결과는 판별자에 의해서만 평가되고, 판별자는 지속적으로 향상되기 때문에 훈련 과정의 다른 지점에서 평가된 손실을 비교할 수 없다.
하이퍼파라미터
- batch normalization
- dropout
- learning rate
- activation layer
- convolutional filter
- kernel size
- batch size
- latent dimension
📌 회색이 DCGAN, 청록색은 WGAN
| Discriminator | Generator |
|---|---|
 |  |
 |  |
결과 이미지는 아래와 같다.

WGAN-GP

기존 GAN의 손실함수는 아래와 같이 계산된다.
d_real_loss = criterion(real_predictions, real_noisy_labels)
g_loss = criterion(fake_predictions, real_labels)
와서스테인 손실함수는 [0,1] 마지막 층에 시그모이드 함수를 제거하여 예측 범위가 [0,1]이 아닌 어떤 숫자가 될 수 있도록 한다. 하지만 비평가(=판별자)에 추가적인 제약을 가해야 한다.
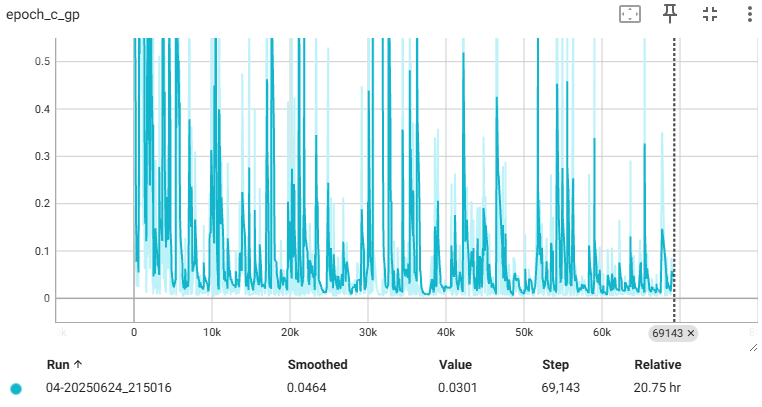
임의의 두 입력 이미지에 대해 다음 예측에 관해서 비율을 제한한다. 가중치를 클립핑 하다보면 학습 속도가 크게 감소하게 된다. 여기서 추가한 방법으로는 gradient가 norm 1을 벗어날 경우 gradient penalty를 주어 비평가에 추가 시켜 립시츠 제약 조건을 직접 강제한다.
c_wass_loss = torch.mean(fake_pred) - torch.mean(real_pred)
c_gp = self.gradient_penalty(batch_size, real_images, fake_images)
c_loss = c_wass_loss + self.gp_weight * c_gp
# Gradient Penalty
norm = torch.sqrt(torch.sum(gradients**2, dim=1))
gp = torch.mean((norm - 1.0) ** 2)
훈련 과정동안 그래디언트는 일부 무작위 지점에서 보간한 이미지들을 이용한다. 안타깝게도 WGAN의 특성상 훈련시간이 긴 관계로 epoch 40에서 끊었다. 원래라면은 일반 모델에 비해 안정적으로 훈련이 된다.
| Critic loss | Generator loss |
|---|---|
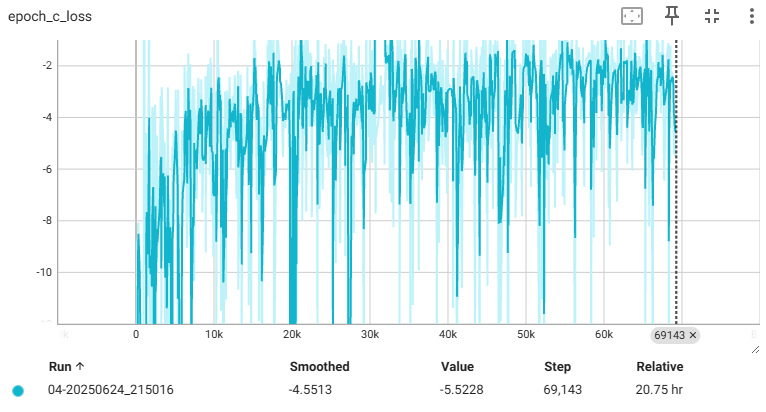 | |
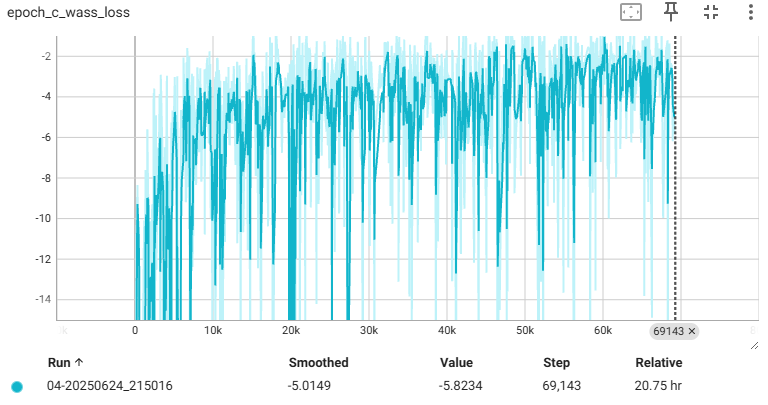 |  |
미완성이지만.. 결과 이미지는 아래와 같다.

CGAN
속성을 조건으로 부여하는 GAN 모델 형태. 레이블과 관련된 정보를 생성자와 비평자에게 전달하는 차이점이 있다. 조건을 부여함으로써, 출력을 제어할 수 있다. 또한 개별 특성이 분리되도록 잠재공간을 구성할 수 있다.
마찬가지로 미완성이지만.. 결과 이미지는 아래와 같다.

해당 코드와 torch migration은 아래 repository에 첨부하였다.
- Authors

- Name
- Amelia Young
- GitHub
- @ameliacode